

문서번호 : 11-1680343
Document Information
•
최초 작성일 : 2023.10.10
•
최종 수정일 : 2023.10.25
•
이 문서는 아래 버전을 기준으로 작성되었습니다.
◦
SinglestoreDB : 8.1.2
Goal
•
SingleStoreDB 의 vector 함수인 dot_product 를 활용하여 이미지에서 인식한 얼굴의
유사도 비교
Step
1.
영화 영상 파일에서 프레임을 추출하여, 프레임(이미지)을 SingleStoreDB 에 저장
2.
추출한 프레임에서 얼굴 인식 모델을 활용하여 인식한 얼굴 이미지를 임베딩하여
vector 데이터로 변환 후 DB에 저장
3.
flask 로 해당하는 얼굴과 가장 유사한 얼굴 이미지를 유사도 순위로 웹페이지에 표현
SingleStoreDB 버전 : 8.1.20
CPU : 4
MEMORY : 8 GB
Node :
MA - 1개
LEAF - 1개
Partition : 4
Python 3.8
DDL 및 DML
•
DDL 및 DML 쿼리는 아래 파이썬 코드 (img2vec.py, flask_image.py) 에 포함되어 있습니다.
1.
img2vec.py : 프레임 추출 및 임베딩 그리고 테이블에 data ingestion 하는 코드
2.
flask_image.py : 얼굴 유사도 비교 결과를 flask 를 이용하여 웹에 표현하는 코드
프레임 추출 및 얼굴 인식 후 DB 에 저장
1. 영화 영상 파일에서 프레임 추출
•
저작권이 만료된 영화 2편에서 각 25프레임 단위로 프레임 추출
1.
Teachers_pet2.mkv (선생님의 애완동물 part2) (흑백 영화)
2.
Gone_with_the_Wind_part1.mkv (바람과 함께 사라지다 part1)
2. 프레임에서 얼굴 인식
•
facenet_pytorch 의 얼굴 인식 모델인 MTCNN 을 사용하여 추출한 프레임에서 얼굴 인식하여
얼굴 좌표 획득 및 임베딩하여 vector 데이터로 변환
•
pytorch 기반 라이브러리로 보다 사용이 용이하고,
한 이미지에서 여러 얼굴 인식 및 얼굴 좌표 (랜드마크) 추출이 가능하며,
dlib 그리고 기존 MTCNN 보다 얼굴 인식 측면에서 속도가 더 빠른
pytorch로 구현된 facenet_pytorch 의 MTCNN 을 사용하여 얼굴 인식.
•
vggface2 데이터 셋으로 사전 학습한 InceptionResnetV1 모델로 이미지 임베딩 수행
파이썬 코드 : img2vec.py
import os
import cv2
import numpy as np
import torch
from facenet_pytorch import MTCNN, InceptionResnetV1
from PIL import Image
import singlestoredb as s2
import traceback
import io
import json
# 데이터베이스 연결 정보
HOST = 'IP'
PORT = 3306
USER = 'DB 유저'
PASSWORD = '비밀번호'
DATABASE = '데이터 베이스'
frm_tbl = 'img_frame_fx25'
fc_tbl = 'face2vec_fx25'
# 데이터베이스 연결
conn = s2.connect(
host=HOST,
user=USER,
password=PASSWORD,
database=DATABASE
)
# create table
frame_tbl = f"""create table if not exists {frm_tbl} (
img_id int(11) not null,
frame_nm varchar(255),
image longblob,
key (id) using hash,
shard key(frame_nm),
sort key(id)
);"""
face_tbl = f"""create table if not exists {fc_tbl} (
face_id int(11) not null,
frame_nm varchar(255),
face json,
vector blob,
key (id) using hash,
shard key(frame_nm),
sort key(id)
);"""
cur = conn.cursor()
cur.execute(frame_tbl)
cur.execute(face_tbl)
# MTCNN과 InceptionResnetV1 모델 로드
mtcnn = MTCNN(keep_all=True, min_face_size=120)
resnet = InceptionResnetV1(pretrained='vggface2').eval()
frame_sql = f"INSERT INTO {frm_tbl} (img_id , frame_nm, image) VALUES (%s, %s, %s)"
face_sql = f"INSERT INTO {fc_tbl} (face_id , frame_nm, face, vector) VALUES (%s, %s, %s, json_array_pack(%s))"
# nomalize vector (벡터 정규화)
def normalize_vector(vector):
norm = torch.norm(vector, p=2, dim=1, keepdim=True)
normalized_vector = vector / norm
return normalized_vector
#id
cnt = 0
fcnt = 1
# vectorize
def extract_frames(video_path, frame_interval, batch_size):
global cnt
global fcnt
# Load video
cap = cv2.VideoCapture(video_path)
# check the file loaded
if not cap.isOpened():
print("Error: can't load the file.")
return
batch = []
batch_number = 1
frame_count = 0
while True:
# read frames
ret, frame = cap.read()
# finished the read
if not ret:
break
# save frames by interval
if frame_count % frame_interval == 0:
batch.append(frame)
if len(batch) == batch_size:
print('batch length :', len(batch))
for frame in batch:
frame = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
img_cv2 = cv2.cvtColor(np.array(frame), cv2.COLOR_RGB2BGR)
frame_title = f"{filename}_{cnt}"
faces = mtcnn(frame)
# 얼굴 좌표 및 확률 추출
boxes, probs = mtcnn.detect(frame)
if boxes is not None and len (boxes) > 0:
for idx, face in enumerate(faces):
prob = probs[idx]
if prob > 0.99 :
# resnet 모델을 사용하여 face 이미지를 임베딩하여 벡터 데이터로 변환
img_embedding = resnet(face.unsqueeze(0))
#위에서 정의한 정규화 함수를 이용하여 벡터 데이터 정규화
img_embedding = normalize_vector(img_embedding)
# 데이터 베이스에 벡터 데이터를 저장하기 위해 타입 변경
# Numpy 배열인 임베딩된 벡터 데이터를 flatten 하여 1차원 배열로 변환하고, 리스트 -> 문자열로 변환
img_embedding = str(img_embedding.flatten().tolist())
box = boxes[idx]
box_list = box.tolist()
box_json = json.dumps(box_list)
face_data =(fcnt, frame_title, box_json, img_embedding)
cur.execute(face_sql, face_data)
fcnt += 1
cnt += 1
# 이미지를 바이너리 데이터로 변환
byte_arr = io.BytesIO()
frame.save(byte_arr, format='PNG')
image_data = byte_arr.getvalue()
frame_data = (cnt, frame_title, image_data)
cur.execute(frame_sql, frame_data)
conn.commit()
batch=[]
batch_number += 1
frame_count += 1
if batch:
for frame in batch:
frame = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
img_cv2 = cv2.cvtColor(np.array(frame), cv2.COLOR_RGB2BGR)
frame_title = f"{filename}_{cnt}"
faces = mtcnn(frame)
boxes, probs = mtcnn.detect(frame)
if boxes is not None and len (boxes) > 0:
for idx, face in enumerate(faces):
prob = probs[idx]
if prob > 0.99 :
img_embedding = resnet(face.unsqueeze(0))
img_embedding = normalize_vector(img_embedding)
img_embedding = str(img_embedding.flatten().tolist())
box = boxes[idx]
box_list = box.tolist()
box_json = json.dumps(box_list)
face_data =(fcnt, frame_title, box_json, img_embedding)
cur.execute(face_sql, face_data)
fcnt += 1
cnt += 1
# 이미지를 바이너리 데이터로 변환
byte_arr = io.BytesIO()
frame.save(byte_arr, format='PNG')
image_data = byte_arr.getvalue()
frame_data = (cnt, frame_title, image_data)
cur.execute(frame_sql, frame_data)
conn.commit()
# Close video reader
cap.release()
frame_count = int(frame_count / frame_interval)
print(f"Finished loading frames. Total {frame_count} saved.")
# Set variables
input_directory = "/home/opc/mv_frame/movies" # mkv 파일 디렉토리 경로
frame_interval = 25 # 일정한 간격으로 프레임 저장 (25 프레임)
batch_size = 10
# Iterate through mkv files in the input directory
try :
for filename in os.listdir(input_directory):
if filename.endswith(".mkv"):
video_path = os.path.join(input_directory, filename)
extract_frames(video_path, frame_interval, batch_size)
except Exception as e:
traceback.print_exc()
finally:
conn.close()
Python
복사
Ingestion 확인
singlestore> select img_id, frame_nm, sha1(image) from img_frame_fx25 where img_id < 6 order by 1;
+--------+---------------------+------------------------------------------+
| img_id | frame_nm | sha1(image) |
+--------+---------------------+------------------------------------------+
| 1 | Teachers_pet2.mkv_0 | 4e163e6e3158e76aa9b9dad47de93c65c96370dd |
| 2 | Teachers_pet2.mkv_1 | c404dedc08c73da67b21350afe3ae48ea5886770 |
| 3 | Teachers_pet2.mkv_2 | abb0467097181b86954d17da0acb1bb7cc406096 |
| 4 | Teachers_pet2.mkv_3 | a6d28afc96ae0c5da6f2a595ed97b9305822f740 |
| 5 | Teachers_pet2.mkv_4 | 8e2dcf463baef83e854e5505854a339e3b80ba63 |
+--------+---------------------+------------------------------------------+
5 rows in set (0.04 sec)
singlestore> select face_id, frame_nm, face, sha1(vector) from face2vec_fx25 where face_id <6 order by 1;
+---------+----------------------+-----------------------------------------------------------------------------+------------------------------------------+
| face_id | frame_nm | face | sha1(vector) |
+---------+----------------------+-----------------------------------------------------------------------------+------------------------------------------+
| 1 | Teachers_pet2.mkv_1 | [841.9851684570312,142.64962768554688,963.5681762695312,308.54241943359375] | 6acd6e0617eae9830c9276eeb48aded66d51f89b |
| 2 | Teachers_pet2.mkv_2 | [784.7305297851562,143.9194793701172,912.7191772460938,314.43682861328125] | 9bdabe286cb3d43c251fc66ba3cf0ade9c184cde |
| 3 | Teachers_pet2.mkv_3 | [747.0670166015625,140.2769317626953,874.9608764648438,310.2846374511719] | 1f3e35c6a64a23cf37b864d1cba346271ea59c3d |
| 4 | Teachers_pet2.mkv_13 | [332.0965881347656,391.7582092285156,439.3731689453125,583.3365478515625] | cc0130da4c89f5dd9d91893cc78806fa9e5920f8 |
| 5 | Teachers_pet2.mkv_14 | [1507.8375244140625,449.70953369140625,1641.097412109375,637.3809814453125] | 2d03b19ba5c98f6b4b640455b5bfd148f678aa64 |
+---------+----------------------+-----------------------------------------------------------------------------+------------------------------------------+
5 rows in set (0.04 sec)
SQL
복사
특정 얼굴 유사도 표현
Flask로 웹 페이지에 이미지와 얼굴 표현
•
특정 face_id 를 지정하여, 해당하는 vector 값과 가장 유사한 얼굴 이미지를 포함하는 프레임을 유사도 순위로 표현.
•
DOT_PRODUCT 를 이용하여 얼굴 유사도를 구하고 높은 값부터 20개를 정렬하여 선택. (Top 20 KNN)
•
위에서 선택한 얼굴 20개를 EUCLIDEAN_DISTANCE 이용하여 서로 다른 프레임 간 유클리디안
거리가 0.3 미만이면 중복된 얼굴로 인식하여 보다 작은 크기의 사이즈로 이미지 표시. (중복 제거는 data에 따라 다양한 알고리즘 선정 필요함. 예시를 위해 vector간 거리를 사용함)
dot_product 함수를 이용한 유사도 top4 조회 예시
# face_id 가 100인 얼굴의 이미지 유사도 비교 top4 조회 쿼리
WITH target AS (
SELECT vector as v2 FROM face2vec_fx25 WHERE face_id = 100 # 기준 face_id
)
SELECT v.face_id, i.frame_nm, dot_product(v.vector, target.v2) as score, substring(json_array_unpack(v.vector),1, 110) as vector
FROM img_frame_fx25 i
INNER JOIN face2vec_fx25 v ON i.frame_nm = v.frame_nm
INNER JOIN target
ORDER BY score DESC
LIMIT 5;
# top4 조회 결과 및 vector 데이터 확인
+---------+-----------------------+--------------------+----------------------------------------------------------------------------------------------------------------+
| face_id | frame_nm | score | vector |
+---------+-----------------------+--------------------+----------------------------------------------------------------------------------------------------------------+
| 100 | Teachers_pet2.mkv_104 | 1 | [-0.0192908347,-0.0224674344,0.0060667675,-0.0262606274,0.0808363631,0.0225105044,0.0154247871,-0.00753672561, |
| 101 | Teachers_pet2.mkv_105 | 0.9452268481254578 | [-0.0211227089,-0.00780974748,0.00126591069,-0.0703039244,0.0416311659,0.0327570438,0.00976078026,-0.013043608 |
| 99 | Teachers_pet2.mkv_103 | 0.9119338989257812 | [0.00312176137,-0.00704365829,0.00900752097,-0.0737070814,0.0437549539,0.0156371333,-0.0124957021,0.0157040302 |
| 92 | Teachers_pet2.mkv_88 | 0.8868334889411926 | [0.00233438541,-0.00629964471,0.00138104905,-0.0759592205,0.0319078825,0.0234120488,0.0157014783,-0.0069763497 |
| 103 | Teachers_pet2.mkv_111 | 0.8767971992492676 | [0.00145188696,-0.00690847356,-0.00848316774,-0.0913699418,0.037625622,0.0291228425,0.0242910013,-0.0098315281 |
+---------+-----------------------+--------------------+----------------------------------------------------------------------------------------------------------------+
5 rows in set (0.11 sec)
SQL
복사
파이썬 코드 : flask_image.py
from flask import Flask, render_template, Response
import singlestoredb as s2
import cv2
import numpy as np
import ast
import base64
import traceback
app = Flask(__name__)
# Database connection settings
HOST = 'IP'
PORT = 3306
USER = 'DB 유저'
PASSWORD = '비밀번호'
DATABASE = '데이터 베이스'
# Define a route to display images
@app.route('/display_image/<int:_id>')
def display_image(_id):
# Database connection
conn = s2.connect(
host=HOST,
user=USER,
password=PASSWORD,
database=DATABASE
)
cur = conn.cursor()
try:
# Execute the query to fetch image and face data
query = """
with
basis_face as (
select face_id, frame_nm, face, vector
from face2vec_fx25 where face_id = %s),
similar_faces as (
select b.face_id, b.frame_nm, b.face, b.vector, dot_product(a.vector, b.vector) similarity
from basis_face a, face2vec_fx25 b
),
face_set as (
select face_id, frame_nm, similarity, face, vector
from similar_faces
order by similarity desc
limit 20),
face_distance as (
select a.face_id face_id_a, b.face_id face_id_b, EUCLIDEAN_DISTANCE(a.vector, b.vector) distance
from face_set a, face_set b
where a.face_id != b.face_id
order by 3),
dup_faces as (
select row_number() over (order by similarity desc) order_id, face_id_a, json_agg(face_id_b) dup_face, similarity
from face_distance, face_set
where distance < 0.3
and face_distance.face_id_a = face_set.face_id
group by face_id_a),
dup_faces_result as (
select a.order_id order_id, a.face_id_a face_id
, a.dup_face dup_face
, case when sum(json_array_contains_double(b.dup_face, a.face_id_a)) > 0 then 'Y' else 'N' end dup_exists
from dup_faces a, dup_faces b
where a.order_id >= b.order_id
group by a.order_id, a.face_id_a
)
select y.*, z.image
from (
select a.face_id, a.frame_nm, face, a.similarity, dup_face
from face_set a left join dup_faces_result b
on a.face_id = b.face_id
where dup_exists is null or dup_exists = 'N'
) y,
img_frame_fx25 z
where y.frame_nm = z.frame_nm
order by similarity desc;
"""
cur.execute(query, (_id))
# Fetch the results
results = cur.fetchall()
# 이미지 데이터를 저장할 리스트
images = []
for result in results:
id, frame_nm, face, score, dup, image_blob = result
if dup is not None :
flag = 0
# Convert image_blob to numpy array
img_array = np.frombuffer(image_blob, np.uint8)
image = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
# Draw a rectangle around the face
face_coords = face
x1, y1, x2, y2 = face_coords
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)
image = cv2.resize(image, (550, 343))
# Encode image to base64
_, img_encoded = cv2.imencode('.jpg', image)
img_base64 = base64.b64encode(img_encoded).decode('utf-8')
# image info
img_info = {
"Face ID": id,
"Frame Name": frame_nm,
"Similarity Score": score,
}
images.append((flag, img_base64, img_info))
for dup_face in dup :
flag = 0
dup_sql = f"""
with dp_face as (
select face_id
from face2vec_fx25 where face_id = {dup_face}
)
select a.*, b.image
from (
select f.face_id, f.face, i.frame_nm
from face2vec_fx25 f
inner join img_frame_fx25 i on f.frame_nm = i.frame_nm
inner join dp_face on f.face_id = dp_face.face_id) a,
img_frame_fx25 b
where a.frame_nm = b.frame_nm;
"""
cur.execute(dup_sql)
dup_results = cur.fetchone()
dp_face_id, dp_face, dp_frame_nm, dp_image = dup_results
# Convert image_blob to numpy array
img_array = np.frombuffer(dp_image, np.uint8)
image = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
# Draw a rectangle around the face
face_coords = dp_face
x1, y1, x2, y2 = face_coords
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)
image = cv2.resize(image, (400, 203))
# Encode image to base64
_, img_encoded = cv2.imencode('.jpg', image)
img_base64 = base64.b64encode(img_encoded).decode('utf-8')
# image info
img_info = {
"Face ID": dp_face_id,
"Frame Name": dp_frame_nm,
}
images.append((flag, img_base64, img_info))
else :
flag = 1
# Convert image_blob to numpy array
img_array = np.frombuffer(image_blob, np.uint8)
image = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
# Draw a rectangle around the face
face_coords = face
x1, y1, x2, y2 = face_coords
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)
image = cv2.resize(image, (550, 343))
# Encode image to base64
_, img_encoded = cv2.imencode('.jpg', image)
img_base64 = base64.b64encode(img_encoded).decode('utf-8')
# image info
img_info = {
"Face ID": id,
"Frame Name": frame_nm,
"Similarity Score": score,
}
images.append((flag, img_base64, img_info))
# 이미지 데이터를 HTML 템플릿으로 전달하고 이미지를 표시
return render_template('display_image.html', images=images)
except Exception as e:
traceback.print_exc()
return str(e), 500
finally:
cur.close()
conn.close()
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=True)
Python
복사
HTML: display_image.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Image Display</title>
<style>
@media (max-width: 600px) {
.image-container {
flex-direction: column;
}
.image-wrapper {
width: 100%;
}
}
</style>
</head>
<body>
<div class="image-container">
<div class="image-column">
{% set is_last_1 = true %}
{% for is_1, img_base64, img_info in images %}
{% if is_1 %}
{% if not is_last_1 %}
</div> <!-- 1인 이미지 세로 배치를 마친 경우 닫기 -->
<br><br> <!-- 1인 이미지 사이에 빈 줄 추가 -->
{% endif %}
<div class="image-column"> <!-- 1인 이미지 세로 배치 시작 -->
<div class="image-wrapper"> <!-- 1인 이미지 세로 배치 시작 -->
<img src="data:image/jpeg;base64,{{ img_base64 }}" alt="Image">
<p>Face ID: {{ img_info['Face ID'] }}</p>
<p>Frame Name: {{ img_info['Frame Name'] }}</p>
<p>Similarity Score: {{ img_info['Similarity Score'] }}</p>
</div>
</div>
{% set is_last_1 = true %}
{% else %}
<div class="image-wrapper" style="display: inline-block;"> <!-- 0인 이미지 가로 배치 -->
<img src="data:image/jpeg;base64,{{ img_base64 }}" alt="Image">
<p>Face ID: {{ img_info['Face ID'] }}</p>
<p>Frame Name: {{ img_info['Frame Name'] }}</p>
<p>Similarity Score: {{ img_info['Similarity Score'] }}</p>
</div>
{% set is_last_1 = false %}
{% endif %}
{% endfor %}
</div>
</div>
</body>
</html>
HTML
복사
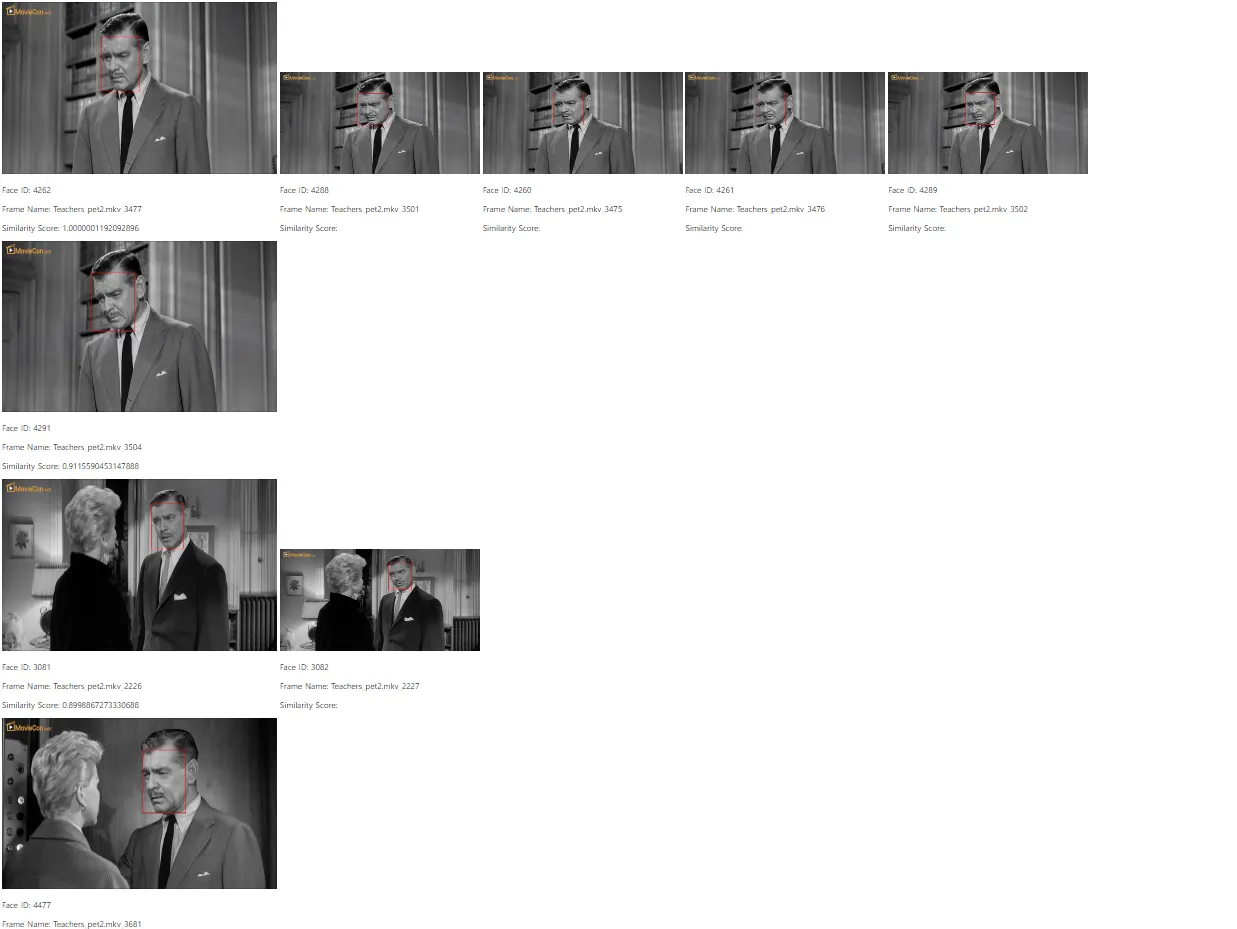
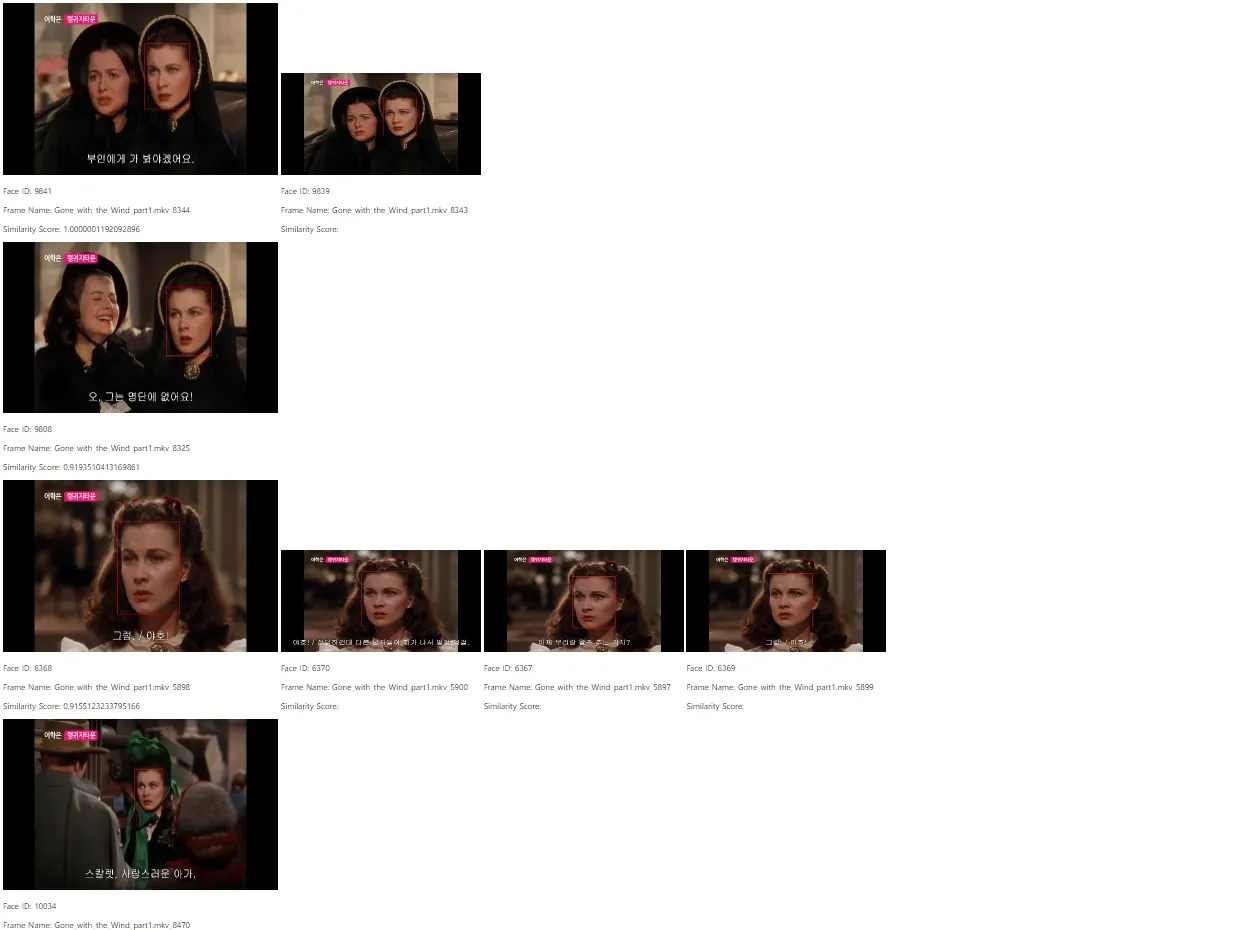
Flask 웹 페이지 확인
•
왼쪽 가장 위에 있는 얼굴 이미지 기준(예시 1의 Facd ID : 4262)으로 유사도 분석
•
기준 얼굴 이미지 바로 아래에 세로로 유사도가 높은 얼굴 이미지들을 차례로 나열
•
가로로 나열된 크기가 보다 작은 이미지들은 가장 왼쪽의 이미지에서
중복된 얼굴로 인식된 이미지를 표현
예시 1
예시 2
References
History
일자 | 작성자 | 비고 |
2023.10.10 | min | |
2023.10.25 | min | 설명 및 쿼리 추가 |

