

문서번호 : 11-2172434
Document Information
•
최초 작성일 : 2024.02.06
•
최종 수정일 : 2024.02.13
•
이 문서는 아래 버전을 기준으로 작성되었습니다.
◦
SinglestoreDB : 8.5.4
CPU : 4
MEMORY : 16 GB
Node :
MA - 1개
LEAF - 1개
Partition : 4
Python 3.8
Goal
•
Hybrid Search 를 이용하여 검색 문장에 가장 적합한 인물 profile Top3를 검색 한다.
◦
Hybrid Search = Semantic Search + Lexical Search
◦
Semantic Search : 인물 profile data 와 Search 문장을 각각 임베딩 하여 벡터 데이터 생성.
그 후 벡터 함수인 dot_product 를 이용하여 Search 문장의 벡터와 가장 유사한 프로필 벡터 데이터 검색 = Similar Search 결과 확인
◦
Lexical Search : 인물 data와 Search 문장을 각각 형태소 분석, 형태소 분석 칼럼을 Fulltext index 로 지정. 그 후 Match against 구문을 사용하여 Search 문장과 유사한 프로필
문장 검색 = Text Search 결과 확인
◦
Hybrid Search : Semantic Search 와 Lexical Search 의 결과 값을 미리 정한 알고리즘에 따라 reordering 하여 결과 도출.
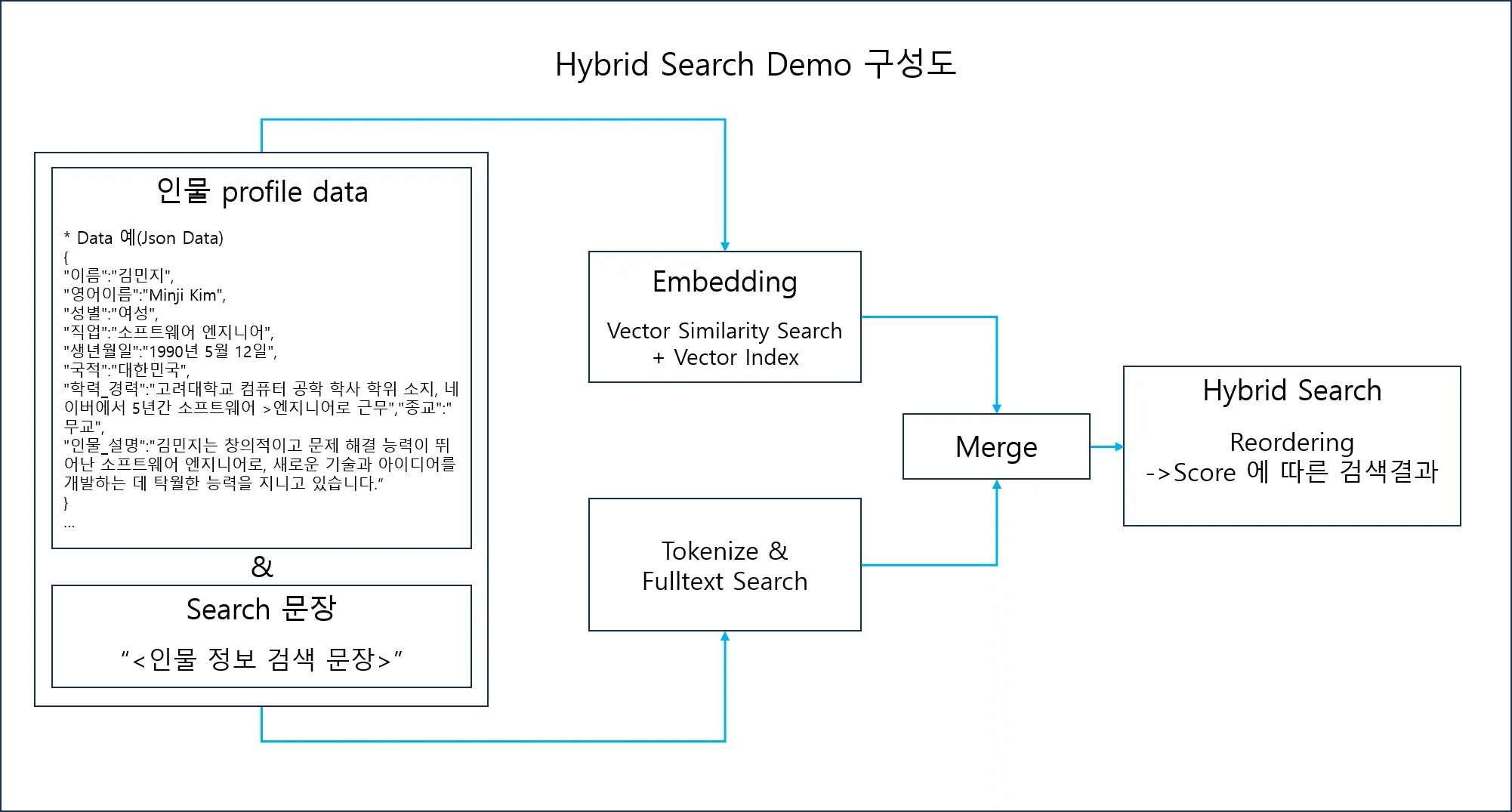
Hybrid Search Demo(profile Search) 구성도
결과
Step
1.
테이블 생성 & 인물 Profile 데이터(Json data) Ingestion
•
Embedding → 벡터 데이터
•
Tokenize → Fulltext Search 데이터
2.
Hybrid Search를 이용하여 인물 Profile 검색
•
Vector Similarity Search + Fulltext Search → Reordering 하여 결과 도출
DDL 및 DML
•
DDL 및 DML 쿼리는 아래 파이썬 코드 (crt_prftbl.py, hybrd_srch.py) 에도 포함되어 있습니다.
1.
crt_prftbl.py : 테이블 생성 & 인물 Profile 데이터 적재
2.
hybrd_srch.py : 인물 검색 결과를 hybrid Search 의 결과로 도출
테이블 생성
•
vector데이터 칼럼 : Embedding 모델의 차원에 맞게, vector 데이터 타입 차원 설정
•
vector Index : ANN 서치 활용 (Demo 에서는 IVF_FLAT 인덱스 사용)
•
형태소 분석 칼럼 : Toknizer로 형태소 분석 후 적재, Fulltext index로 지정
create table if not exists prf_tbl (
id_num int(11) not null,
profile json,
token text, # 형태소 칼럼
vec vector(768) not null, # vector 칼럼 (768 차원)
vector index vec_idx1 (vec) index_options '{{"index_type":"IVF_FLAT", "nlist":2, "nprobe":1}}', # vector 인덱스
primary key (id_num),
fulltext(token) # fulltext 인덱스
);
SQL
복사
Hybrid Search 쿼리
•
벡터 데이터 & 임베딩한 검색 문장의 Similarity Search 결과 : S1
•
검색 문장 형태소 Serach 의 MATCH AGAINST 결과 : S2
•
Hybrid Search Score : Reordering Score = (S1 + S2) / 2
◦
Demo 에서 의 Reordering은, 임의로 각 결과의 합의 1/2 로 설정함
◦
Reordering 의 알고리즘은 자체적으로 선정 필요함
select
profile, # 인물 Profile 출력
vec <*> json_array_pack(<Embedding 한 검색 문장>) as s1, # Similarity Score
match(token) against (<검색 문장 형태소 분석 결과>) as s2, # Fulltext Search Score
(s1+s2)/2 as score # Hybrid Search Score
from prf_tbl
order by score desc
limit 3
SQL
복사
데모 코드
인물 Profile 데이터
•
가상의 인물 Json 프로필 10개
UTF-8 character set 사용
테이블 생성 & 인물 Profile 데이터(Json data) Ingestion
파이썬 코드 : crt_prftbl.py
•
Embedding 모델 : “huggingface” 의 “jhgan/ko-sroberta-multitask” 사용
◦
Multi lingual 모델 & 한글 Embedding 중 Similarity Score 가 높은 모델 사용
# 라이브러리
import singlestoredb as s2
import json
from langchain.embeddings import HuggingFaceEmbeddings
import torch
from konlpy.tag import Okt
# DB 접속정보
HOST = 'localhost'
PORT = 3306
USER = '<유저>'
PASSWORD = '<패스워드>'
DATABASE = '<데이터 베이스>'
TABLE = 'prf_tbl'
# DB 연결
conn = s2.connect(
host=HOST,
user=USER,
password=PASSWORD,
database=DATABASE
)
# 테이블 생성
tbl_sql = f"""
create table if not exists {TABLE} (
id_num int(11) not null,
profile json,
token text,
vec vector(768) not null,
vector index vec_idx1 (vec) index_options '{{"index_type":"IVF_FLAT", "nlist":2, "nprobe":1}}',
primary key (id_num),
fulltext(token)
);"""
cur = conn.cursor()
cur.execute(tbl_sql)
# 데이터 ingestion 쿼리
isrt_sql = f"INSERT INTO {TABLE} (id_num, profile, token, vec) VALUES (%s, %s, %s, %s)"
# 형태소분석
okt = Okt()
# 임베딩 벡터 정규화함수
def normalize_vector(vector):
vector_tensor = torch.tensor(vector, dtype=torch.float32)
vector_tensor = vector_tensor.unsqueeze(0) # 차원 추가
norm = torch.norm(vector_tensor, p=2, dim=1, keepdim=True) # L2 정규화
normalized_vector = vector_tensor / norm
return normalized_vector.tolist()[0] # 리스트로 변환하여 반환
# huggingfaces
embeddings = HuggingFaceEmbeddings(model_name="jhgan/ko-sroberta-multitask")
# 프로필 데이터 삽입
with open('profiles1.txt', 'r', encoding='utf-8') as file:
id_num = 0 # id
for line in file:
id_num += 1
profile_data = json.loads(line) # json 데이터파일 load
profile_values = ' '.join(profile_data.values()) # json 의 value 값만 추출
tokens = okt.morphs(profile_values) # Tokenize, 형태소 분석
tokens = ' '.join(tokens)
profile_vector = embeddings.embed_query(profile_values) # Embedding
profile_vector = normalize_vector(profile_vector) # 정규화
profile_vector = str(profile_vector)
profile_json = json.dumps(profile_data) # json profile 데이터
cur.execute(isrt_sql, (id_num, profile_json, tokens, profile_vector)) # 데이터 ingestion
optmz_sql = f"optimize table {TABLE} full"
cur.execute(optmz_sql)
conn.commit()
conn.close()
print("=" * 40)
print(f"{id_num} rows 데이터ingestion 완료")
print("=" * 40)
Python
복사
Hybrid Search를 이용하여 인물 Profile 검색
파이썬 코드 : hybrd_srch.py
# 라이브러리
import singlestoredb as s2
import json
from langchain.embeddings import HuggingFaceEmbeddings
import torch
from konlpy.tag import Okt
# DB 접속정보
HOST = 'localhost'
PORT = 3306
USER = '<유저>'
PASSWORD = '<패스워드>'
DATABASE = '<데이터 베이스>'
# DB 연결
conn = s2.connect(
host=HOST,
user=USER,
password=PASSWORD,
database=DATABASE
)
cur = conn.cursor()
# 검색
print("=" * 80)
qstn = input("프로필 검색: ")
print("=" * 80 + "\n")
# 형태소분석
okt = Okt()
tokens = okt.morphs(qstn)
tokens = ' '.join(tokens)
# 임베딩 벡터 정규화함수
def normalize_vector(vector):
vector_tensor = torch.tensor(vector, dtype=torch.float32)
vector_tensor = vector_tensor.unsqueeze(0) # 차원 추가
norm = torch.norm(vector_tensor, p=2, dim=1, keepdim=True) # L2 정규화
normalized_vector = vector_tensor / norm
return normalized_vector.tolist()[0] # 리스트로 변환하여 반환
# huggingfaces
embeddings = HuggingFaceEmbeddings(model_name="jhgan/ko-sroberta-multitask")
# 프로필 검색문장 Embedding
qstn_vector = embeddings.embed_query(qstn)
qstn_vector = normalize_vector(qstn_vector)
qstn_vector = str(qstn_vector)
# ----------- Demo 코드 실행 시 제외 (vector index 동작 확인용 코드) : Begin -----------
# ANN 인덱스 검색 확인쿼리
xpln_sql = f"""
explain select
profile,
vec <*> json_array_pack(%s) as s1,
match(token) against (%s) as s2,
(s1+s2)/2 as score
from prf_tbl
order by s1 desc
limit 3
"""
cur.execute(xpln_sql, (qstn_vector, tokens,))
xpln_rslt = cur.fetchall()
# explain 쿼리 확인
for rs in xpln_rslt :
print(rs)
# ----------- Demo 코드 실행 시 제외 (vector index 동작 확인용 코드) : End -----------
# Search 쿼리
srch_sql = f"""
select
profile,
vec <*> json_array_pack(%s) as s1,
match(token) against (%s) as s2,
(s1+s2)/2 as score
from prf_tbl
order by score desc
limit 3
"""
cur.execute(srch_sql, (qstn_vector, tokens,))
results = cur.fetchall()
# 결과 출력 & 확인
separator = "*" * 30
output = [separator,
f'Question : {qstn}',
f'Token : {tokens}']
i = 0
for res in results:
i += 1
output.append("-----------")
output.append(f"#{i}#")
for key, val in res[0].items():
output.append(f"{key} : {val}")
output.extend([f"Total Score: {res[3]}",
f"Vec score : {res[1]}",
f"Text score : {res[2]}"])
output.append(separator)
print('\n'.join(output))
Python
복사
ANN Index Search 확인
hybrd_srch.py 파이썬 코드의 explain 쿼리 확인
•
explain쿼리를 통해 ANN 동작을 확인하기 위한 코드로서,
데모 코드 실행 시에는 해당 코드 제외
# ANN 인덱스 검색 확인쿼리
xpln_sql = f"""
explain select
profile,
vec <*> json_array_pack(%s) as s1,
match(token) against (%s) as s2,
(s1+s2)/2 as score
from prf_tbl
order by s1 desc
limit 3
"""
cur.execute(xpln_sql, (qstn_vector, tokens,))
xpln_rslt = cur.fetchall()
# explain 쿼리 확인
for rs in xpln_rslt :
print(rs)
Python
복사
vector Index 사용 확인
•
vector index 동작 확인 : INTERNAL_VECTOR_SEARCH
('Project [remote_0.profile, remote_0.s1, remote_0.s2, remote_0.score]',)
('TopSort limit:5 [remote_0.s1 DESC]',)
('Gather partitions:all alias:remote_0 parallelism_level:segment',)
("Project [prf_tbl.profile, DOT_PRODUCT(prf_tbl.vec,JSON_ARRAY_PACK('[-0.08343324065208435, 0.008895773440599442, 0.04481888562440872, -0.0775635838508606, 0.0565468966960907, -0.00961839035153389, -0.04823928698897362, -0.03210621327161789, -0.048955123871564865, -0.04540256783366203, 0.055186785757541656, 0.00972767360508442, 0.04668761417269707, -0.023273343220353127, 0.04557356610894203, 0.06394023448228836, -0.004792636726051569, -0.01738288626074791, -0.011180720292031765, 0.008260964415967464, -0.01...]",)
("TopSort limit:5 [DOT_PRODUCT(prf_tbl.vec,JSON_ARRAY_PACK('[-0.08343324065208435, 0.008895773440599442, 0.04481888562440872, -0.0775635838508606, 0.0565468966960907, -0.00961839035153389, -0.04823928698897362, -0.03210621327161789, -0.048955123871564865, -0.04540256783366203, 0.055186785757541656, 0.00972767360508442, 0.04668761417269707, -0.023273343220353127, 0.04557356610894203, 0.06394023448228836, -0.004792636726051569, -0.01738288626074791, -0.011180720292031765, 0.008260964415967464, -0.013191510923206806,...]",)
("ColumnStoreFilter [INTERNAL_VECTOR_SEARCH(0, (JSON_ARRAY_PACK('[-0.08343324065208435, 0.008895773440599442, 0.04481888562440872, -0.0775635838508606, 0.0565468966960907, -0.00961839035153389, -0.04823928698897362, -0.03210621327161789, -0.048955123871564865, -0.04540256783366203, 0.055186785757541656, 0.00972767360508442, 0.04668761417269707, -0.023273343220353127, 0.04557356610894203, 0.06394023448228836, -0.004792636726051569, -0.01738288626074791, -0.011180720292031765, 0.008260964415967464, -0.0131915109232068...]",)
('ColumnStoreScan v_test.prf_tbl, SORT KEY __UNORDERED () table_type:sharded_columnstore',)
Bash
복사
데모 실행 & 전체 결과 확인
•
제의 & 제안 (데모 결과를 기준으로)
◦
Fulltext Search(Lexical search) Score 비중을 높인다면,
보다 변별력 있는 결과가 도출 될 것으로 판단됨
◦
Total score가 특정 Score 미만인 경우는 결과에서 제외.
아래 Hybrid Search 결과 예시에서는 0.25 미만의 결과 제외하여,
각 검색 문장에서 얻고자 하는 프로필(요리사, 의사) 만 가져오도록 한다.
crt_prftbl.py 실행

테이블 확인
select * from prf_tbl order by 1 limit 5;
SQL
복사

Hybrid Search 예시 1
•
검색 문장 : “한식 요리를 하고 서울에 있는 레스토랑에서 일하는 요리사”

•
결과
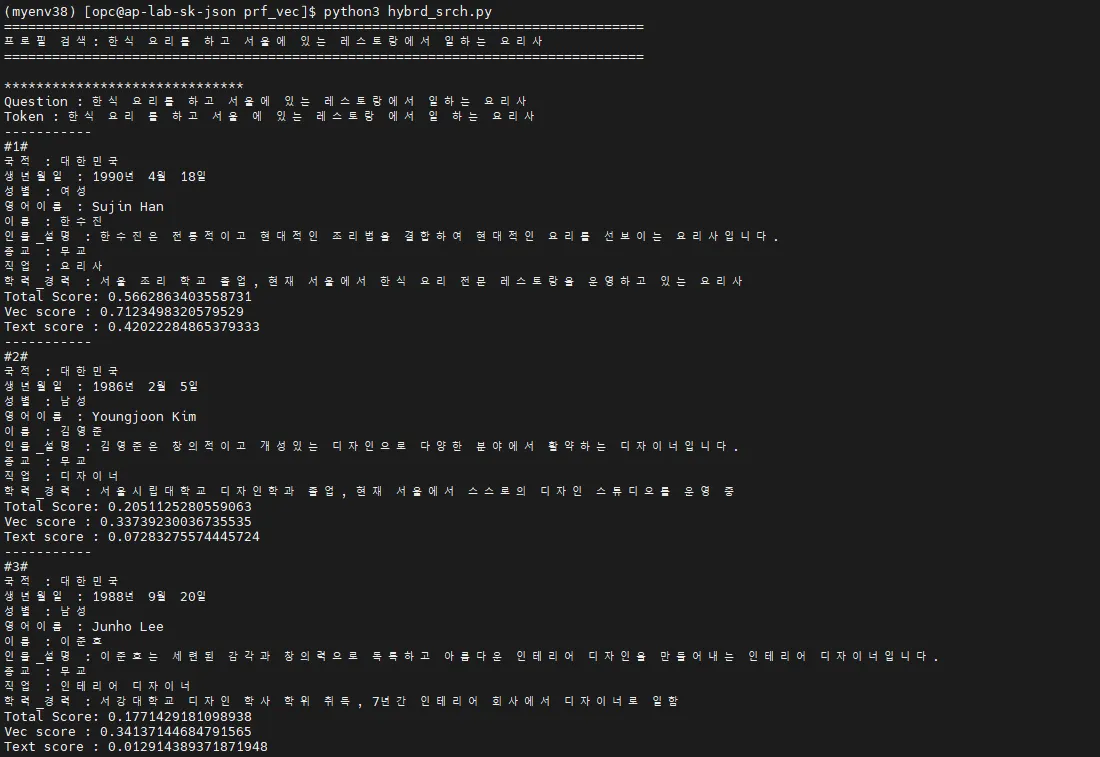
Hybrid Search 예시 2
•
검색 문장 : “연세대학교 출신의 전문의 세브란스 병원에서 근무하는 의사”

•
결과
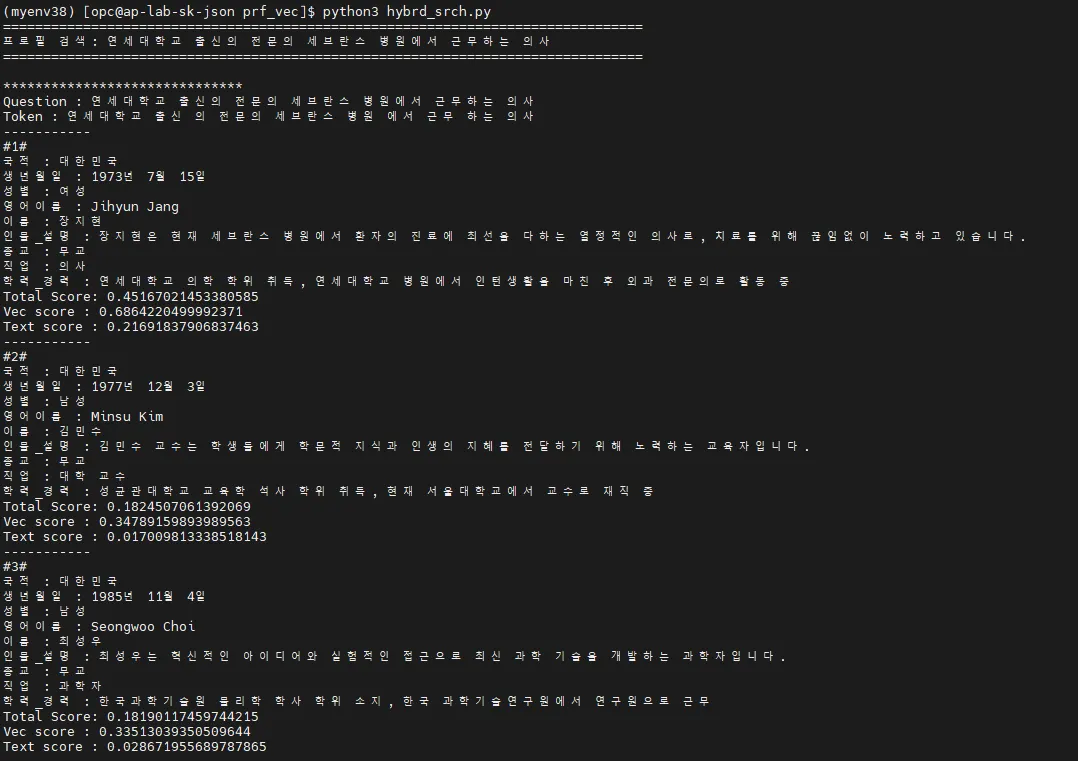
References
History
일자 | 작성자 | 비고 |
2024.02.06 | min | 최초 작성 |
2024.02.13 | min | 문구 추가, 수정 |

