

문서번호 : 11-1814136
Document Information
•
최초 작성일 : 2023.12.29
•
최종 수정일 : 2025.10.17
•
이 문서는 아래 버전을 기준으로 작성되었습니다.
◦
Singlestore : 8.1
Goal
•
Sort Key 선정 시, 고려해야 할 부분을 알아봅시다.
Solution
1. Sort Key 정의
•
컬럼스토어(Columnstore) 테이블의 경우 하나의 행(row)이 여러 개의 컬럼 세그먼트(Column Segment)로 나뉘어 저장됩니다. 각각의 컬럼 세그먼트는 하나의 기준에 의해 모두 동일하게 정렬되어야 합니다.
•
Sort Key 는 이 때 사용되는 정렬 기준 컬럼을 말하며 하나 또는 여러 개의 컬럼들로 구성됩니다.
2. Sort Key 목적
•
각각의 컬럼 세그먼트는 최대 100만개의 행 또는 5MB 크기를 가질 수 있으며 대용량 테이블의 경우 다수의 컬럼 세그먼트가 생성됩니다.
•
컬럼 세그먼트에 저장된 각 컬럼의 최솟값 및 최댓값을 비롯한 메타데이터는 메모리에 저장되며 추후 WHERE 조건절에서 Sort Key 를 조건으로 사용하면 Segment Elimination 이 수행됩니다.
•
Segment Elimination 이 수행되면 전체 컬럼 세그먼트를 모두 조회하는 대신 조건에 맞는 행들이 저장된 컬럼 세그먼트만을 선택하여 빠르게 조회할 수 있습니다.
3. Sort Key 특징
•
Sort Key 는 컬럼스토어 테이블에만 지정할 수 있습니다.
•
Sort Key 는 컬럼스토어 테이블 당 오직 하나만 지정할 수 있습니다.
•
Sort Key 는 하나 이상의 컬럼으로 구성될 수 있습니다.
•
Sort Key 를 명시적으로 지정하지 않거나, sort key() 구문을 사용하여 아무 key도 지정하지 않을 경우 데이터는 정렬되지 않고 입력된 순서대로 저장됩니다.
•
Sort Key 는 오름차순 및 내림차순으로 지정할 수 있습니다.
◦
오름차순 : SORT KEY(column_name)
◦
내림차순 : SORT KEY(column_name DESC)
◦
지정된 정렬 순서로만 조회되며 정렬 순서의 역순으로 조회하는 것은 지원되지 않습니다.
•
Sort Key 는 alter 명령어로 변경할 수 없습니다.
◦
테이블의 데이터 분포가 물리적으로 변경되기 때문에 지원하지 않습니다.
◦
Sort Key 변경이 필요할 경우 일반적으로 다음과 같이 작업합니다.
▪
추가 테이블 생성 → INSERT … SELECT 로 데이터 복제 → 원본 및 추가 테이블명 변경
4. Sort Key 선택 시 고려 사항
•
Segment Elimination
◦
Sort Key 에 대한 가장 중요한 고려 사항은 Segment Elimination양을 늘리는 것입니다.
◦
컬럼 세그먼트의 최솟값, 최댓값 같은 메타데이터는 쿼리 실행 시 해당 컬럼 세그먼트가 필터 조건에 해당되는지 여부를 결정합니다.
◦
필터 조건에 부합하지 않는 경우 해당 세그먼트는 읽지 않고 조회 작업에서 제외됩니다. 이를 Segment Elimination 이라고 합니다.
◦
WHERE 조건절에 자주 사용되고 조회 대상 데이터를 대폭 줄일 수 있는 조건을 가진 컬럼을 Sort Key 로 지정하는 것이 좋습니다.
•
Sorted Scan
◦
ORDER BY 구문으로 빈번하게 지정되는 컬럼을 Sort Key 로 지정할 수 있습니다.
◦
일반적으로 테이블 스캔(Scan) 후 정렬하는 것보다 이미 정렬된 상태의 세그먼트를 스캔하는 것의 성능이 좋기 때문입니다.
•
Background Merger 작업 최소화
◦
Sorted row segment group 상태를 유지하기 위해 background merger 가 주기적으로 컬럼 세그먼트간 Sort Key 값이 중첩되는 것을 해소하는 세그먼트 병합(merge) 작업이 자동적으로 수행됩니다.
◦
예를 들어 입력 시간 컬럼을 Sort Key 로 지정할 경우 가장 최근의 컬럼 세그먼트들만 자동 병합 대상이 되므로 병합 작업량 및 병합 작업 시간이 최소화될 수 있습니다.
•
Low Cardinality 컬럼 먼저 배치
◦
Sort Key 컬럼이 여러 개인 경우 일반적으로 카디날리티(cardinality)가 낮은 컬럼을 앞에 배치하는 것이 Segment Elimination 에 도움이 됩니다.
◦
예를 들어 Sort Key 로 (insert_timestamp, region_id) 가 지정되었을 경우 micro 초단위의 insert_timestamp 는 카디날리티가 높습니다.
◦
insert_timestamp 에서 segment elimination 이 발생하려면 조회 시 BETWEEN AND 와 같은 non-equal 조건을 사용할 필요가 높고 일, 월 단위로 조회할 경우 region_id 는 segment elimination 에 도움을 주지 못할 가능성이 대단히 높습니다.
◦
따라서 이 경우에는 필터 조건의 정밀도(예: 월, 일, 시, 분) 등에 맞춰 Computed Column 을 생성하고 이를 Sort Key 로 포함시켜 카디날리티를 낮추는 것이 segment elimination 측면에서 도움이 됩니다.
•
Sort Key 와 Shard Key 연관성
◦
Sort Key 와 Shard Key 는 각각 다르게 지정할 수 있습니다.
◦
단일 파티션 조인 성능을 향상시키기 위해 다른 테이블과 동일한 Shard Key 를 선택하고 일반적인 조회 조건과 일치하는 컬럼들(예, event_timestamp 또는 event_type)을 Sort key 로 선택하는 것은 매우 일반적입니다.
•
Sort Key 와 Primary Key 연관성
◦
일반적으로 Primary Key 가 조회 조건에 주로 포함되지 않거나 다른 테이블과 빈번하게 조인되지 않는 다면 Sort Key 역시 Primary Key 와 다르게 지정하고 주로 많이 사용하는 필터 조건에 맞게 지정합니다.
◦
Primary Key 로 auto increment 컬럼을 사용한다면 background merge 작업을 최소화하기 위해 Primary Key 를 Sort Key 의 일부 또는 전부로 포함시킬 수 있습니다.
5. Sorted row segment group 예시
•
다음 products 테이블은 Price 컬럼을 Sort Key 로 지정했습니다.
CREATE TABLE products (
ProductId INT,
Color VARCHAR(10),
Price INT,
Quantity INT,
SORT KEY (Price)
);
SQL
복사
•
아래 표는 products 테이블 중 하나의 파티션 데이터를 임의로 나열한 것입니다.
+-----------+-------+-------+----------+
| ProductId | Color | Price | Quantity |
+-----------+-------+-------+----------+
| 1 | Red | 10 | 2 |
| 2 | Red | 20 | 2 |
| 3 | Black | 20 | 2 |
| 4 | White | 30 | 2 |
| 5 | Red | 20 | 2 |
| 6 | Black | 10 | 2 |
| 7 | White | 25 | 2 |
| 8 | Red | 30 | 2 |
| 9 | Black | 50 | 2 |
| 10 | White | 15 | 2 |
| 11 | Red | 5 | 2 |
| 12 | Red | 20 | 2 |
| 13 | Black | 35 | 2 |
| 14 | White | 30 | 2 |
| 15 | Red | 4 | 2 |
+-----------+-------+-------+----------+
SQL
복사
•
아래 그림처럼, 데이터는 여러 개의 로우 세그먼트(Row Segment)로 분할됩니다.
◦
로우 세그먼트는 논리적인 개념으로 여러 개의 컬럼 세그먼트로 구성된 다수의 행 집합을 말합니다.
◦
컬럼 세그먼트는 일반적으로 수만 개의 행을 가지고 있지만 아래에서는 이해를 돕기 위해 세그먼트당 5개의 행(row)만 있다고 가정합니다.
◦
또한, x N 규칙을 사용하여 값이 N번 반복됨을 나타냅니다.
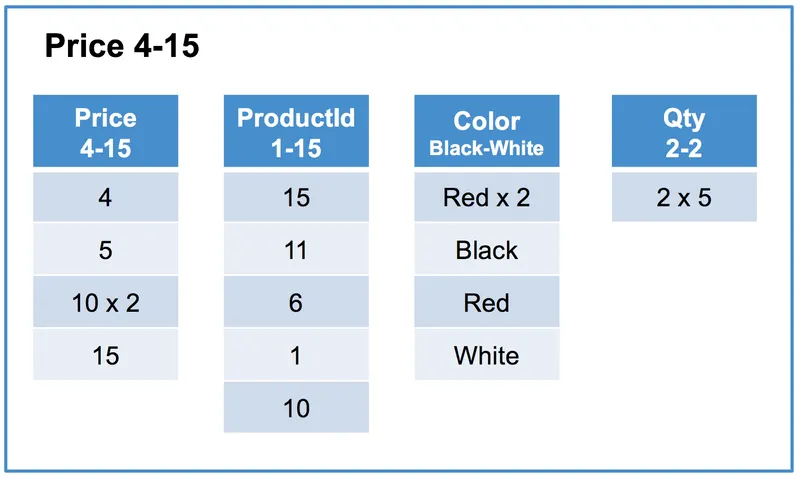
첫번째 로우 세그먼트
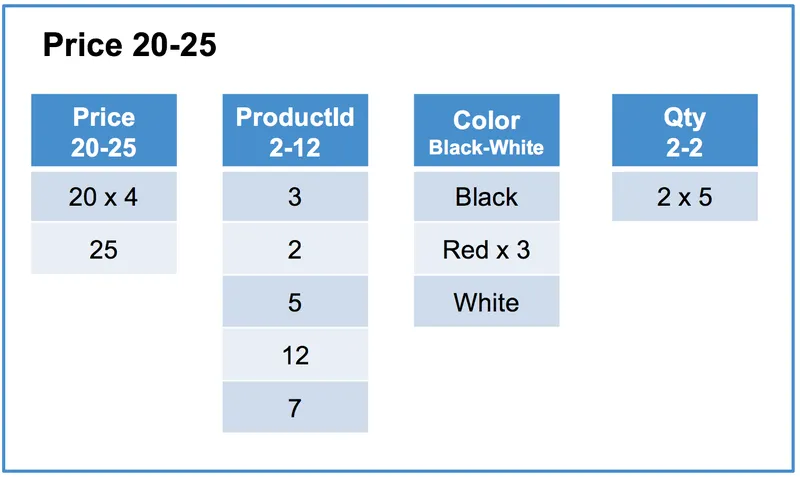
두번째 로우 세그먼트
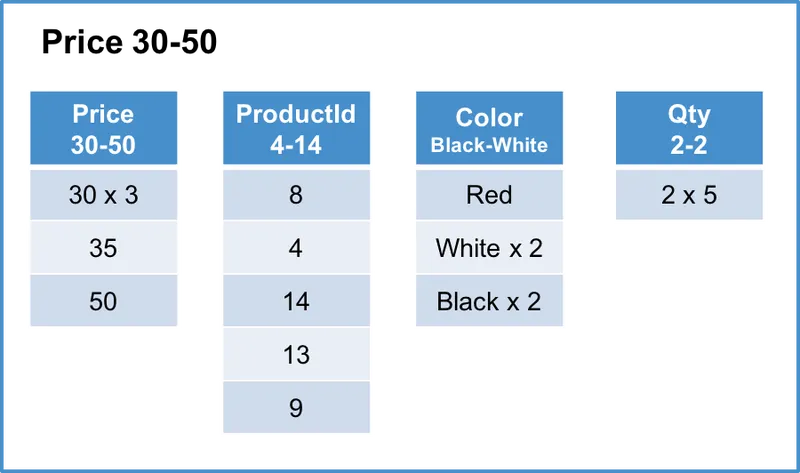
세번째 로우 세그먼트
•
Price 컬럼의 서로 다른 범위(4-15, 20-25, 30-50)를 포함하는 3개의 로우 세그먼트가 생성됩니다.
•
각 로우 세그먼트는 동일한 5개의 행을 가지며 컬럼별로 별도의 세그먼트로 구성됩니다.
•
각 컬럼 세그먼트의 순서는 Sort Key 에 의해 정렬된 행의 순서와 동일합니다.
•
Segment Elimination
◦
Sort Key 컬럼을 조회 조건으로 사용하는 쿼리의 경우, 로우 세그먼트 그룹 안에서 데이터 범위가 겹치는 로우 세그먼트가 없으므로 매우 효율적인 Segment Elimination 이 수행됩니다.
◦
아래의 쿼리는 첫 번째 로우 세그먼트만 조회하고 다른 세그먼트들은 읽지 않습니다.
SELECT AVG(Price), AVG(Qty)
FROM Products
WHERE Price BETWEEN 1 AND 10;
JavaScript
복사
References
History
일자 | 작성자 | 비고 |
2023.12.29 | wee | 최초 작성 |
2024.01.03 | jsnoh | 수정 |
2025.10.17 | jwy | SingleStoreDB → SingleStore |

